在當今數據驅動的時代,如何高效、可靠地存儲和訪問海量結構化數據,是許多大型科技公司面臨的核心挑戰之一。Google 內部開發的 Bigtable 系統,正是為應對這一挑戰而誕生的一種高性能、可擴展的分布式結構化數據存儲系統。它并非傳統的關系型數據庫,而是一個稀疏的、分布式的、持久化的多維排序映射表,專為處理 PB 級別的大規模數據而設計,并深刻影響了后來如 Apache HBase、Cassandra 等眾多開源分布式數據庫的發展。
一、核心數據模型:一個多維度的映射表
Bigtable 的數據模型簡潔而強大。它將所有數據組織成一張巨大的表。這張表的行鍵(Row Key)是任意的字符串,對數據的讀取至關重要,因為數據按行鍵的字典順序排列。每一行數據又由多個列族(Column Family)組成,列族是訪問控制的基本單位,需要在表創建時預先定義。每個列族下包含任意數量的列限定符(Column Qualifier),從而在列族內形成了動態的、稀疏的列空間。表中的每個數據單元格(Cell)由行鍵、列族、列限定符唯一確定,并包含一個時間戳版本,從而實現數據的多版本管理。這種 (row:string, column:string, timestamp:int64) → string 的映射模型,提供了極大的靈活性,既能模擬簡單的鍵值存儲,也能通過精心設計行鍵和列來模擬更復雜的數據結構。
二、系統架構與關鍵組件
Bigtable 的架構設計充分體現了分布式系統的核心思想:分而治之與冗余備份。其核心組件包括:
- Bigtable 客戶端庫:應用程序通過客戶端庫訪問 Bigtable。客戶端庫不直接與底層存儲通信,而是與 Tablet Server 交互,并緩存了重要的元數據位置信息。
- Master 服務器:承擔管理員的角色,主要負責將 Tablet(數據表被按行范圍分割后的連續片段)分配給 Tablet Server,監測 Tablet Server 的增刪與負載均衡,以及處理表模式變更(如創建列族)等元數據操作。值得注意的是,Master 并不參與實際的數據讀寫流程,這避免了其成為系統瓶頸。
- Tablet Server:系統的工作主力,每個 Tablet Server 管理一組 Tablet(通常為數十至上千個)。它直接處理對其管理的 Tablet 的讀寫請求,并在 Tablet 規模過大時負責對其進行分割。數據在內存和磁盤間流動,持久化層依賴于 Google 的分布式文件系統 GFS(現為 Colossus)。
- Chubby 服務:一個高可用的分布式鎖服務,在 Bigtable 中扮演著至關重要的角色。它用于確保 Master 選舉的唯一性、存儲 Bigtable 數據的引導位置(即 Root Tablet 的位置)、存儲 Tablet Server 的注冊信息以及訪問控制列表。Chubby 的可用性直接關系到 Bigtable 集群的可用性。
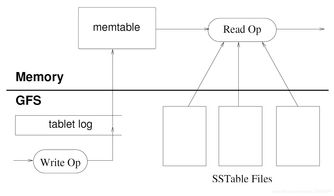
數據的持久化存儲采用“日志-內存表-磁盤文件”的多層結構。寫入操作首先被提交到提交日志(存儲在GFS),然后插入到內存中的有序結構(MemTable)中。當 MemTable 大小達到閾值,它會被凍結并轉換為不可變的 SSTable(Sorted String Table)格式文件寫入GFS。SSTable 是持久化的、內部有序的不可變數據文件。讀取操作需要合并 MemTable 和多個 SSTable 中的數據。定期的壓縮(Compaction)過程負責合并多個 SSTable,清理已刪除的數據,以優化讀取性能和控制存儲空間。
三、作為數據處理與存儲服務的特性
Bigtable 不僅僅是一個存儲系統,它更是一個為上層應用提供高效數據處理能力的基礎服務。
- 強大的可擴展性:通過增加 Tablet Server 即可線性地擴展集群的存儲容量和吞吐量。表被自動分割成多個 Tablet 分布到眾多服務器上,實現了負載的分散。
- 高性能:設計目標之一就是應對高吞吐、低延遲的應用場景。數據模型和存儲格式的優化、客戶端元數據緩存、以及將 SSTable 加載到本地磁盤(在 GFS 之上)等機制,共同保障了快速的讀寫訪問。
- 高可用性與可靠性:數據通過 GFS 進行多副本存儲,保證了數據的持久性。Tablet 可以在 Tablet Server 之間動態遷移,當某個服務器失效時,其管理的 Tablet 會被 Master 迅速重新分配到其他可用服務器上,從而恢復服務。
- 靈活的適用性:盡管數據模型簡單,但通過巧妙設計行鍵(如將反轉的域名“com.google.www”作為行鍵以實現同一域名下網頁的連續存儲),Bigtable 能夠高效支持從網頁索引、Google Earth、Google Analytics 到個性化推薦等極其多樣化的 Google 內部服務,展示了其作為通用底層存儲服務的強大適配能力。
- 與數據處理生態的集成:在 Google 內部,Bigtable 與 MapReduce、Spanner、Flume 等數據處理和計算框架緊密集成,構成了完整的大數據生態系統。數據可以方便地從 Bigtable 導出進行批量分析,分析結果也可以寫回 Bigtable 供在線服務低延遲訪問。
四、與影響
Bigtable 的成功在于它在簡單性與功能性、性能與擴展性之間取得了精妙的平衡。它舍棄了關系型數據庫的復雜特性(如跨行事務、復雜的查詢語言),換來了在海量數據規模下無與倫比的擴展性和性能。其論文中闡述的設計理念,如基于列族的數據組織、SSTable 存儲格式、依賴底層分布式文件系統與鎖服務等,已成為構建現代分布式數據庫的教科書級范式。
今天,雖然云原生時代出現了更多新的數據庫類型,但 Bigtable 及其思想遺產,依然是處理超大規模、強一致性要求的在線結構化數據服務的堅實基石,持續為全球各地的企業級應用提供著強大的數據處理和存儲動力。